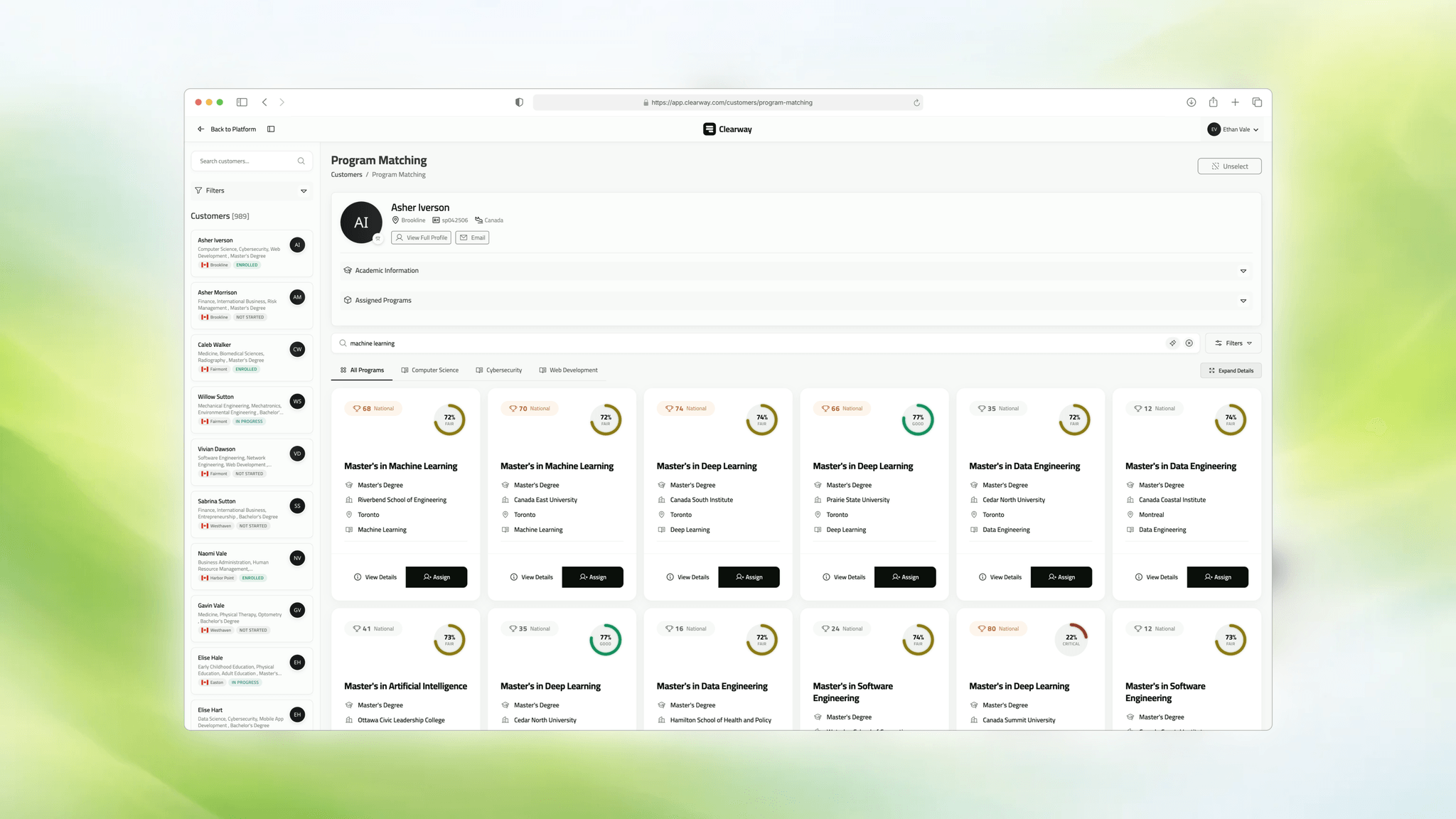

The original matching workflow broke in live advising calls. Advisors were cross-referencing spreadsheet rows by hand, keyword filters missed relevant programs, and core eligibility rules lived in notes fields. I rebuilt that workflow into three connected systems: a 30-table schema, a resumable AI import pipeline, and an explainable matching engine that ranked 19,299 programs in under a second. The result was not a prettier dashboard; it was a workflow advisors could trust during real student calls.
Client name and public URLs changed for confidentiality. Architecture, decisions, and metrics are real.
Why the design looked like this
Three early decisions shaped everything that followed.
Embeddings stayed on program rows instead of moving to separate vector infrastructure. The dataset was 19,299 programs — large enough to need semantic search, small enough that a dedicated vector database would have added operational complexity without proportional gain. MeiliSearch handled hybrid search with embeddings stored alongside relational data, which kept the deployment surface small and the query path fast.
Ordered sheet processing preceded inserts. The spreadsheets contained cross-sheet foreign keys: programs referenced universities, scholarships referenced programs. Importing them out of order would have broken referential integrity silently. The pipeline enforced a strict stage sequence — universities first, then accommodations, then programs, then scholarships — with legacy ID maps persisted between stages to resolve foreign keys that did not yet exist in the new schema.
Explainability was non-negotiable, even though a black-box scorer would have been faster to ship. Advisors needed to defend recommendations in live calls with students and parents. A green score without reasoning would not survive that conversation. So the scoring engine exposed every factor — grade fit, major alignment, scholarship potential, deadline proximity, semantic relevance — as individual line items with positive and negative breakdowns.
Rebuilding the data model
The first decision was sequencing. I did not start by importing data. I started by building the place that data needed to live.
The legacy system was too flat to support intelligent matching. Critical business rules lived inside notes fields: nationality restrictions, scholarship variants, language thresholds, fee structures, and accommodation details. That makes data display possible, but it makes reasoning impossible.
The rules were not simply a data-import problem. They had to be understood before they could be modeled — two weeks of reading scholarship eligibility rules, nationality restrictions, and language thresholds that lived inside notes fields before any schema work could start.
So the first pass rebuilt the foundation as a normalized schema across universities, programs, scholarships, locations, and reference data. The goal was not elegance for its own sake. The goal was queryability. If a future recommendation engine needed to reason about grade requirements, scholarship coverage, or field alignment, those things had to exist as real structured relationships first.
| Decision | Why it mattered |
|---|---|
| 30-table normalized schema | Turned notes-field chaos into data the platform could actually query, filter, and score. |
| Major categories | Gave the future matching engine a structural relevance axis beyond raw keywords. |
| Typed pivots for requirements | Kept thresholds on the actual relationship where they belonged. |
| Embeddings stored on program rows | Avoided premature vector infrastructure while preserving semantic capability. |
| AI autofill in admin forms | Reduced dependency on manual operator discipline during ongoing maintenance. |
The first pass also had to be usable by a non-technical team. That meant the work did not stop at migrations and models. It expanded into a full Livewire CRUD system for programs, universities, settings, language templates, scholarship types, and supporting reference entities. The system had to make clean data easier to enter than dirty data.
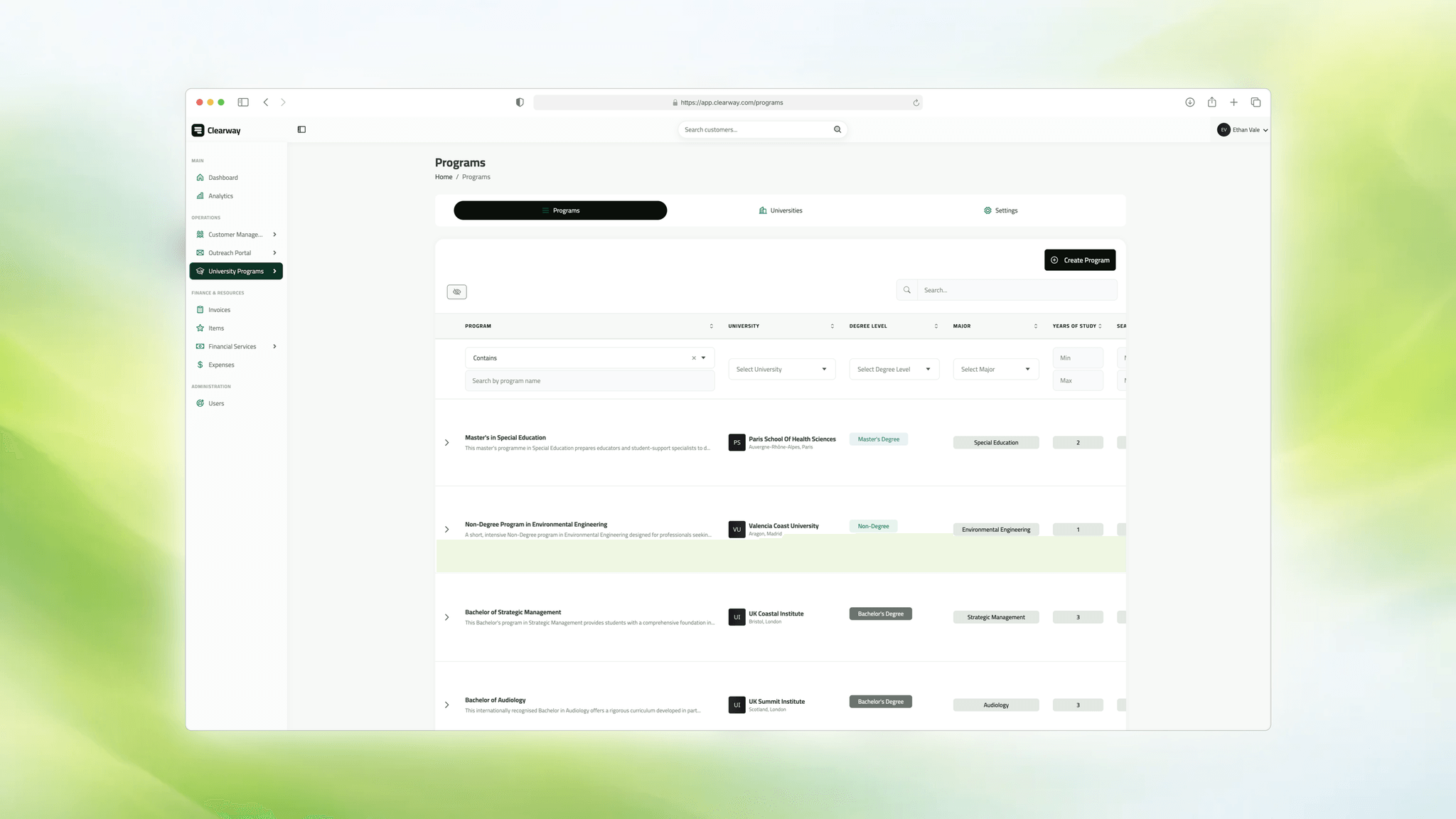
What mattered most here was judgment, not volume. The difficult part was not creating many tables. The difficult part was deciding what deserved first-class structure and what should remain derived or auxiliary.
Making the import resilient
The schema in place changed the next problem, but it did not remove it. The agency's spreadsheets were not clean exports. They were the operating system: inconsistent, human-written, partially structured, and constantly changing.
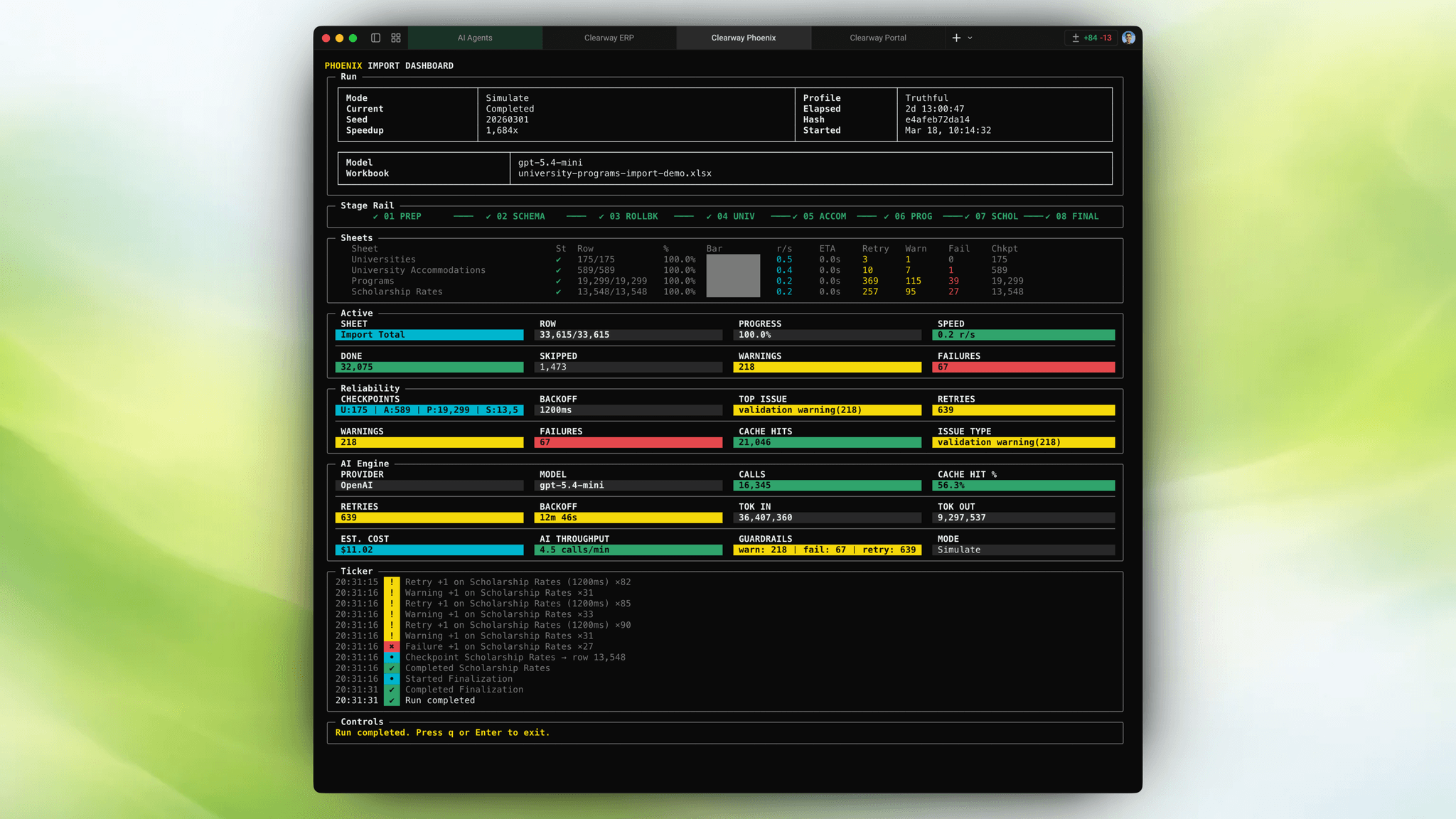

That made manual migration the wrong answer. The problem was not moving rows from one database to another. The problem was reconstructing meaning from natural-language spreadsheet cells and landing that meaning inside a relational model without losing resumability or operational control.
The pipeline processes all four sheets in sequence and persists progress after every row. If a long-running import dies, it resumes from the last checkpoint instead of replaying the entire job. Every AI transformation is cached by row hash, which is why repeated imports of unchanged data do not keep re-spending API cost.
| ETL metric | Value |
|---|---|
| Universities | 175 |
| Accommodations | 590 |
| Programs | 19,299 |
| Scholarships | 13,548 |
| OpenAI calls on the completed run | 16,363 |
| Token volume | 36.4M in / 9.3M out |
| Cache hits | 21,073 |
| Automated retries handled | 640 |
| Completed run cost | $11.05 |
Excel sheets
-> ordered import stages
-> AI row transformation
-> JSON validation
-> FK resolution through legacy ID maps
-> batched inserts
-> state persistence + resume
-> retry-failures for isolated recovery
The important part was not "AI was used." The important part was how the pipeline was engineered around AI unreliability:
- ordered sheet processing preserved cross-sheet foreign key integrity
- content-hash caching controlled cost across reruns
- resumable sessions made overnight debugging survivable
- non-retriable failures were isolated instead of poisoning the full run
- a dense terminal dashboard made reliability, cost, throughput, and failure modes visible while the job was still running
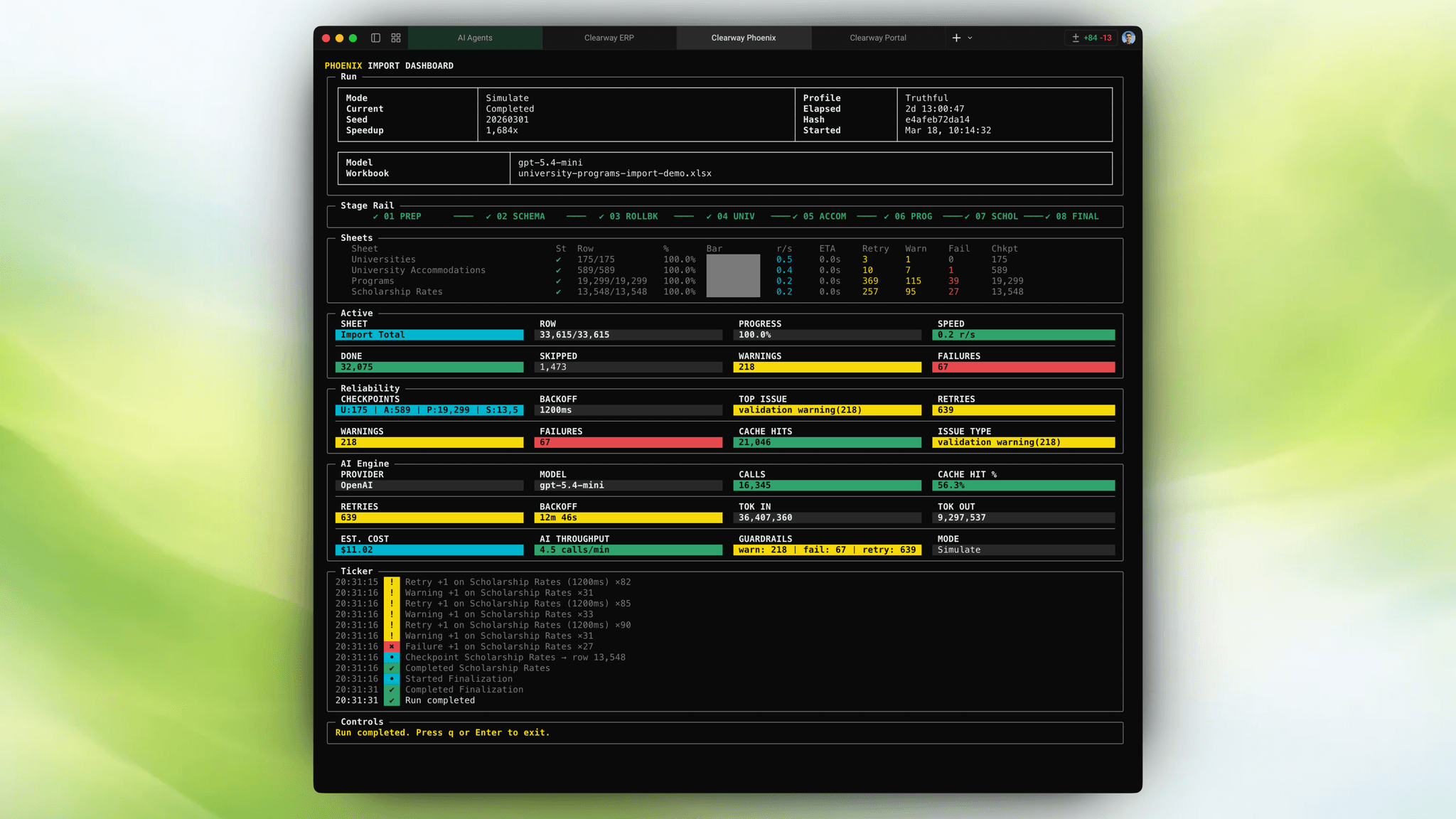
By this point, the hard part was no longer CRUD screens. It was resumability, foreign-key recovery, API cost control, and score explanations that held up in live calls.
From search to assignment
The matching engine made the previous work visible. A better schema and a better import pipeline only mattered if advisors could now make better placement decisions in real time.
The matching engine uses a layered architecture:
- MeiliSearch narrows the candidate set with hybrid search.
- The scoring engine ranks programs against the active student profile.
- The UI exposes the ranking, the explanation, and the post-match workflow in one operating surface.
That architecture existed because V1 had already failed. A literal keyword calculator could never be enough for a domain where adjacent concepts matter. Semantic relevance had to be part of the engine, but it also had to stay explainable enough for live advisor conversations.
| Matching layer | Purpose |
|---|---|
| Hybrid search | Surface relevant candidates from 19,299 programs without exact-keyword dependence. |
| 13-factor scoring model | Rank candidates with weighted business and eligibility logic. |
| Explainability panel | Show why a recommendation scored well or poorly. |
| 18-status assignment lifecycle | Carry the workflow forward after discovery into actual placement operations. |
The final score blended academic fit, major alignment, scholarship potential, ranking, speed, deadlines, seat availability, semantic relevance, and other placement signals. The key product decision was that the score could not act like a black box. A green score without reasoning would not survive a real advisor call.
final score
= weighted criteria total / weighted maximum
+ profile completeness bonus
where the engine can also apply explicit penalties
for grade blockers, weak alignment, or other critical failures
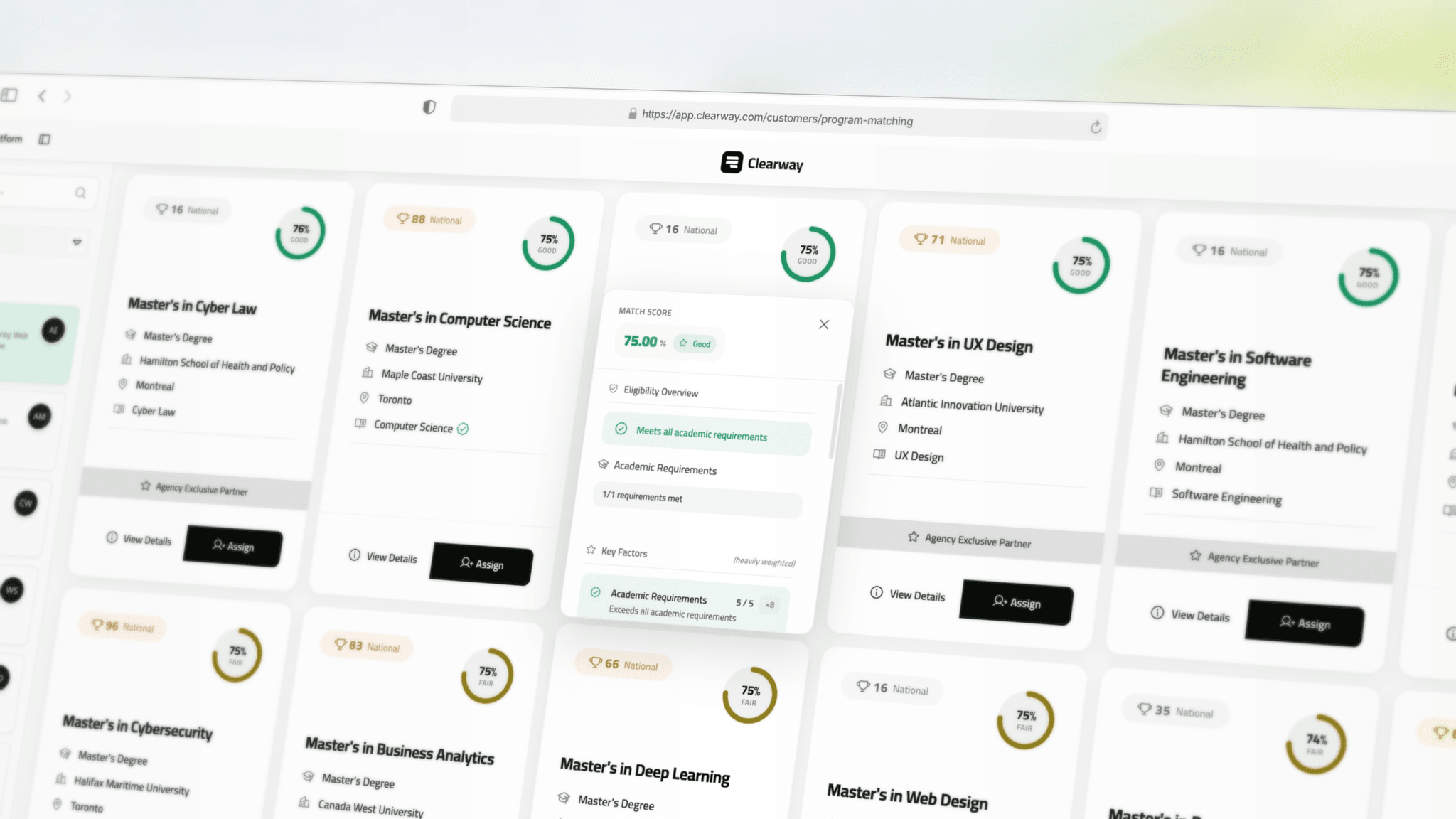
The result was not just a recommendation engine. It was an advisor console that could move from search, to ranking, to assignment, to follow-through without losing context.
Verification and hardening
The ETL could not be tested by running it — each full run took hours, consumed real API spend, and failed silently on edge cases that only surfaced at scale. I used Pest with AI-generated edge-case scenarios to simulate failure modes before running the full pipeline: malformed rows, missing foreign keys, API rate-limit cascades, and partial sheet failures.
Three areas required dedicated verification:
- ETL row-to-row mappings. Every AI transformation was validated against expected output schemas. Rows that produced invalid JSON were caught before insert, isolated, and flagged for manual review instead of poisoning the import.
- Scoring calibration. The 13-factor model was tested against advisor expectations: known-good matches had to score high, known-bad matches had to score low, and edge cases had to produce explainable middle scores instead of false confidence.
- Resumability under failure. The pipeline was deliberately crashed at different stages to verify that checkpoint recovery produced the same final state as an uninterrupted run. Without this, overnight imports that died at 10% completion would have replayed hours of work and re-spent API cost.
Weeks of test-first iteration, not live-run iteration.
Results
| Before | After |
|---|---|
| Advisors manually cross-referenced spreadsheets for hours per student | Advisors received ranked recommendations in under one second |
| Data lived in notes fields and inconsistent cells | Data landed in a structured schema built for filtering and scoring |
| Matching logic was shallow and literal | Matching combined semantic search with explainable weighted ranking |
| Recommendation quality was opaque | Every score exposed its reasoning, penalties, and strengths |
| Work stopped at discovery | Assigned programs entered a tracked lifecycle with prioritization and status changes |
The CEO approved payment immediately after the end-to-end demo and moved straight into scoping the next phase.
Takeaway
Phoenix is the strongest example of the kind of engineering work I want more of: rebuilding brittle operations at the data-model layer, engineering the reliability around messy inputs, and shipping the final surface as a usable product instead of a technical demo.
It was not one feature. It was a sequence of architectural decisions that had to hold together under real operational pressure.